Extending the Metadata Model
You can extend the metadata model by either creating a new Entity or extending an existing one. Unsure if you need to create a new entity or add an aspect to an existing entity? Read metadata-model to understand these two concepts prior to making changes.
To fork or not to fork?
An important question that will arise once you've decided to extend the metadata model is whether you need to fork the main repo or not. Use the diagram below to understand how to make this decision.
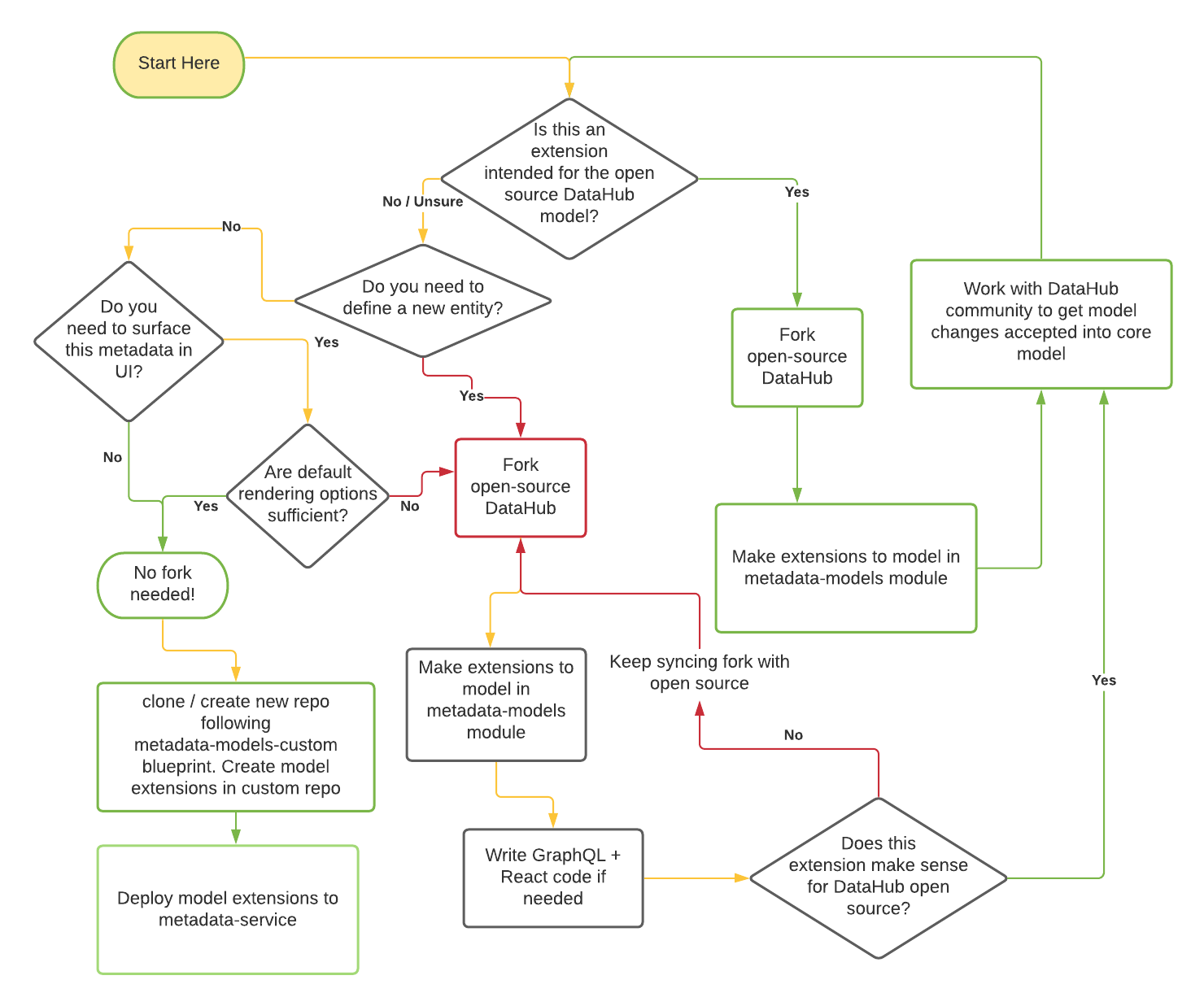
The green lines represent pathways that will lead to lesser friction for you to maintain your code long term. The red lines represent higher risk of conflicts in the future. We are working hard to move the majority of model extension use-cases to no-code / low-code pathways to ensure that you can extend the core metadata model without having to maintain a custom fork of DataHub.
We will refer to the two options as the open-source fork and custom repository approaches in the rest of the document below.
This Guide
This guide will outline what the experience of adding a new Entity should look like through a real example of adding the Dashboard Entity. If you want to extend an existing Entity, you can skip directly to Step 3.
At a high level, an entity is made up of:
- A Key Aspect: Uniquely identifies an instance of an entity,
- A list of specified Aspects, groups of related attributes that are attached to an entity.
Defining an Entity
Now we'll walk through the steps required to create, ingest, and view your extensions to the metadata model. We will use the existing "Dashboard" entity for purposes of illustration.
Step 1: Define the Entity Key Aspect
A key represents the fields that uniquely identify the entity. For those familiar with DataHub’s legacy architecture, these fields were previously part of the Urn Java Class that was defined for each entity.
This struct will be used to generate a serialized string key, represented by an Urn. Each field in the key struct will be converted into a single part of the Urn's tuple, in the order they are defined.
Let’s define a Key aspect for our new Dashboard entity.
namespace com.linkedin.metadata.key
/**
* Key for a Dashboard
*/
@Aspect = {
"name": "dashboardKey",
}
record DashboardKey {
/**
* The name of the dashboard tool such as looker, redash etc.
*/
@Searchable = {
...
}
dashboardTool: string
/**
* Unique id for the dashboard. This id should be globally unique for a dashboarding tool even when there are multiple deployments of it. As an example, dashboard URL could be used here for Looker such as 'looker.linkedin.com/dashboards/1234'
*/
dashboardId: string
}
The Urn representation of the Key shown above would be:
urn:li:dashboard:(<tool>,<id>)
Because they are aspects, keys need to be annotated with an @Aspect annotation, This instructs DataHub that this struct can be a part of.
The key can also be annotated with the two index annotations: @Relationship and @Searchable. This instructs DataHub infra to use the fields in the key to create relationships and index fields for search. See Step 3 for more details on the annotation model.
Constraints: Note that each field in a Key Aspect MUST be of String or Enum type.
Step 2: Create the new entity with its key aspect
Define the entity within an entity-registry.yml file. Depending on your approach, the location of this file may vary. More on that in steps 4 and 5.
Example:
- name: dashboard
doc: A container of related data assets.
keyAspect: dashboardKey
- name: The entity name/type, this will be present as a part of the Urn.
- doc: A brief description of the entity.
- keyAspect: The name of the Key Aspect defined in step 1. This name must match the value in the PDL annotation.
Step 3: Define custom aspects or attach existing aspects to your entity
Some aspects, like Ownership and GlobalTags, are reusable across entities. They can be included in an entity’s set of aspects freely. To include attributes that are not included in an existing Aspect, a new Aspect must be created.
Let’s look at the DashboardInfo aspect as an example of what goes into a new aspect.
namespace com.linkedin.dashboard
import com.linkedin.common.AccessLevel
import com.linkedin.common.ChangeAuditStamps
import com.linkedin.common.ChartUrn
import com.linkedin.common.Time
import com.linkedin.common.Url
import com.linkedin.common.CustomProperties
import com.linkedin.common.ExternalReference
/**
* Information about a dashboard
*/
@Aspect = {
"name": "dashboardInfo"
}
record DashboardInfo includes CustomProperties, ExternalReference {
/**
* Title of the dashboard
*/
@Searchable = {
"fieldType": "TEXT_WITH_PARTIAL_MATCHING",
"queryByDefault": true,
"enableAutocomplete": true,
"boostScore": 10.0
}
title: string
/**
* Detailed description about the dashboard
*/
@Searchable = {
"fieldType": "TEXT",
"queryByDefault": true,
"hasValuesFieldName": "hasDescription"
}
description: string
/**
* Charts in a dashboard
*/
@Relationship = {
"/*": {
"name": "Contains",
"entityTypes": [ "chart" ]
}
}
charts: array[ChartUrn] = [ ]
/**
* Captures information about who created/last modified/deleted this dashboard and when
*/
lastModified: ChangeAuditStamps
/**
* URL for the dashboard. This could be used as an external link on DataHub to allow users access/view the dashboard
*/
dashboardUrl: optional Url
/**
* Access level for the dashboard
*/
@Searchable = {
"fieldType": "KEYWORD",
"addToFilters": true
}
access: optional AccessLevel
/**
* The time when this dashboard last refreshed
*/
lastRefreshed: optional Time
}
The Aspect has four key components: its properties, the @Aspect annotation, the @Searchable annotation and the @Relationship annotation. Let’s break down each of these:
- Aspect properties: The record’s properties can be declared as a field on the record, or by including another
record in the Aspect’s definition (
record DashboardInfo includes CustomProperties, ExternalReference {). Properties can be defined as PDL primitives, enums, records, or collections ( see pdl schema documentation) references to other entities, of type Urn or optionally<Entity>Urn - @Aspect annotation: Declares record is an Aspect and includes it when serializing an entity. Unlike the following two annotations, @Aspect is applied to the entire record, rather than a specific field. Note, you can mark an aspect as a timeseries aspect. Check out this doc for details.
- @Searchable annotation: This annotation can be applied to any primitive field or a map field to indicate that it should be indexed in Elasticsearch and can be searched on. For a complete guide on using the search annotation, see the annotation docs further down in this document.
- @Relationship annotation: These annotations create edges between the Entity’s Urn and the destination of the
annotated field when the entities are ingested. @Relationship annotations must be applied to fields of type Urn. In
the case of DashboardInfo, the
chartsfield is an Array of Urns. The @Relationship annotation cannot be applied directly to an array of Urns. That’s why you see the use of an Annotation override ("/*":) to apply the @Relationship annotation to the Urn directly. Read more about overrides in the annotation docs further down on this page.
After you create your Aspect, you need to attach to all the entities that it applies to.
Constraints: Note that all aspects MUST be of type Record.
Step 4: Choose a place to store your model extension
At the beginning of this document, we walked you through a flow-chart that should help you decide whether you need to maintain a fork of the open source DataHub repo for your model extensions, or whether you can just use a model extension repository that can stay independent of the DataHub repo. Depending on what path you took, the place you store your aspect model files (the .pdl files) and the entity-registry files (the yaml file called entity-registry.yaml or entity-registry.yml) will vary.
- Open source Fork: Aspect files go under
metadata-modelsmodule in the main repo, entity registry goes intometadata-models/src/main/resources/entity-registry.yml. Read on for more details in Step 5. - Custom repository: Read the metadata-models-custom documentation to learn how to store and version your aspect models and registry.
Step 5: Attaching your non-key Aspect(s) to the Entity
Attaching non-key aspects to an entity can be done simply by adding them to the entity registry yaml file. The location of this file differs based on whether you are following the oss-fork path or the custom-repository path.
Here is an minimal example of adding our new DashboardInfo aspect to the Dashboard entity.
entities:
- name: dashboard
- keyAspect: dashBoardKey
aspects:
# the name of the aspect must be the same as that on the @Aspect annotation on the class
- dashboardInfo
Previously, you were required to add all aspects for the entity into an Aspect union. You will see examples of this pattern throughout the code-base (e.g. DatasetAspect, DashboardAspect etc.). This is no longer required.
Step 6 (Oss-Fork approach): Re-build DataHub to have access to your new or updated entity
If you opted for the open-source fork approach, where you are editing models in the metadata-models repository of DataHub, you will need to re-build the DataHub metadata service using the steps below. If you are following the custom model repository approach, you just need to build your custom model repository and deploy it to a running metadata service instance to read and write metadata using your new model extensions.
Read on to understand how to re-build DataHub for the oss-fork option.
NOTE: If you have updated any existing types or see an Incompatible changes warning when building, you will need to run
./gradlew :metadata-service:restli-servlet-impl:build -Prest.model.compatibility=ignore
before running build.
Then, run ./gradlew build from the repository root to rebuild Datahub with access to your new entity.
Then, re-deploy metadata-service (gms), and mae-consumer and mce-consumer (optionally if you are running them unbundled). See docker development for details on how to deploy during development. This will allow Datahub to read and write your new entity or extensions to existing entities, along with serving search and graph queries for that entity type.
(Optional) Step 7: Use custom models with the Python SDK
- Local CLI
- Custom Models Package
If you're purely using the custom models locally, you can use a local development-mode install of the DataHub CLI.
Install the DataHub CLI locally by following the developer instructions.
The ./gradlew build command already generated the avro schemas for your local ingestion cli tool to use.
After following the developing guide, you should be able to emit your new event using the local DataHub CLI.
If you want to use your custom models beyond your local machine without forking DataHub, then you can generate a custom model package that can be installed from other places.
This package should be installed alongside the base acryl-datahub package, and its metadata models will take precedence over the default ones.
$ cd metadata-ingestion
$ ../gradlew customPackageGenerate -Ppackage_name=my-company-datahub-models -Ppackage_version="0.0.1"
<bunch of log lines>
Successfully built my-company-datahub-models-0.0.1.tar.gz and acryl_datahub_cloud-0.0.1-py3-none-any.whl
Generated package at custom-package/my-company-datahub-models
This package should be installed alongside the main acryl-datahub package.
Install the custom package locally with `pip install custom-package/my-company-datahub-models`
To enable others to use it, share the file at custom-package/my-company-datahub-models/dist/<wheel file>.whl and have them install it with `pip install <wheel file>.whl`
Alternatively, publish it to PyPI with `twine upload custom-package/my-company-datahub-models/dist/*`
This will generate some Python build artifacts, which you can distribute within your team or publish to PyPI. The command output contains additional details and exact CLI commands you can use.
Once this package is installed, you can use the DataHub CLI as normal, and it will use your custom models. You'll also be able to import those models, with IDE support, by changing your imports.
- from datahub.metadata.schema_classes import DatasetPropertiesClass
+ from my_company_datahub_models.metadata.schema_classes import DatasetPropertiesClass
(Optional) Step 8: Extend the DataHub frontend to view your entity in GraphQL & React
If you are extending an entity with additional aspects, and you can use the auto-render specifications to automatically render these aspects to your satisfaction, you do not need to write any custom code.
However, if you want to write specific code to render your model extensions, or if you introduced a whole new entity and want to give it its own page, you will need to write custom React and Grapqhl code to view and mutate your entity in GraphQL or React. For instructions on how to start extending the GraphQL graph, see graphql docs. Once you’ve done that, you can follow the guide here to add your entity into the React UI.
Metadata Annotations
There are four core annotations that DataHub recognizes:
@Entity
Legacy This annotation is applied to each Entity Snapshot record, such as DashboardSnapshot.pdl. Each one that is included in the root Snapshot.pdl model must have this annotation.
It takes the following parameters:
- name: string - A common name used to identify the entity. Must be unique among all entities DataHub is aware of.
Example
@Entity = {
// name used when referring to the entity in APIs.
String name;
}
@Aspect
This annotation is applied to each Aspect record, such as DashboardInfo.pdl. Each aspect that is included in an entity’s
set of aspects in the entity-registry.yml must have this annotation.
It takes the following parameters:
- name: string - A common name used to identify the Aspect. Must be unique among all aspects DataHub is aware of.
- type: string (optional) - set to "timeseries" to mark this aspect as timeseries. Check out this doc for details.
- autoRender: boolean (optional) - defaults to false. When set to true, the aspect will automatically be displayed on entity pages in a tab using a default renderer. This is currently only supported for Charts, Dashboards, DataFlows, DataJobs, Datasets, Domains, and GlossaryTerms.
- renderSpec: RenderSpec (optional) - config for autoRender aspects that controls how they are displayed. This is currently only supported for Charts, Dashboards, DataFlows, DataJobs, Datasets, Domains, and GlossaryTerms. Contains three fields:
- displayType: One of
tabular,properties. Tabular should be used for a list of data elements, properties for a single data bag. - displayName: How the aspect should be referred to in the UI. Determines the name of the tab on the entity page.
- key: For
tabularaspects only. Specifies the key in which the array to render may be found.
- displayType: One of
Example
@Aspect = {
// name used when referring to the aspect in APIs.
String name;
}
@Searchable
This annotation is applied to fields inside an Aspect. It instructs DataHub to index the field so it can be retrieved via the search APIs.
It takes the following parameters:
fieldType: string - The settings for how each field is indexed is defined by the field type. Each field type is associated with a set of analyzers Elasticsearch will use to tokenize the field. Such sets are defined in the MappingsBuider, which generates the mappings for the index for each entity given the fields with the search annotations. To customize the set of analyzers used to index a certain field, you must add a new field type and define the set of mappings to be applied in the MappingsBuilder.
Thus far, we have implemented 11 fieldTypes:
KEYWORD - Short text fields that only support exact matches, often used only for filtering
TEXT - Text fields delimited by spaces/slashes/periods. Default field type for string variables.
TEXT_PARTIAL - Text fields delimited by spaces/slashes/periods with partial matching support. Note, partial matching is expensive, so this field type should not be applied to fields with long values (like description)
WORD_GRAM - Text fields delimited by spaces, slashes, periods, dashes, or underscores with partial matching AND word gram support. That is, the text will be split by the delimiters and can be matched with delimited queries matching two, three, or four length tokens in addition to single tokens. As with partial match, this type is expensive, so should not be applied to fields with long values such as description.
BROWSE_PATH - Field type for browse paths. Applies specific mappings for slash delimited paths.
URN - Urn fields where each sub-component inside the urn is indexed. For instance, for a data platform urn like "urn:li:dataplatform:kafka", it will index the platform name "kafka" and ignore the common components
URN_PARTIAL - Urn fields where each sub-component inside the urn is indexed with partial matching support.
BOOLEAN - Boolean fields used for filtering.
COUNT - Count fields used for filtering.
DATETIME - Datetime fields used to represent timestamps.
OBJECT - Each property in an object will become an extra column in Elasticsearch and can be referenced as
field.propertyin queries. You should be careful to not use it on objects with many properties as it can cause a mapping explosion in Elasticsearch.
fieldName: string (optional) - The name of the field in search index document. Defaults to the field name where the annotation resides.
queryByDefault: boolean (optional) - Whether we should match the field for the default search query. True by default for text and urn fields.
enableAutocomplete: boolean (optional) - Whether we should use the field for autocomplete. Defaults to false
addToFilters: boolean (optional) - Whether or not to add field to filters. Defaults to false
boostScore: double (optional) - Boost multiplier to the match score. Matches on fields with higher boost score ranks higher.
hasValuesFieldName: string (optional) - If set, add an index field of the given name that checks whether the field exists
numValuesFieldName: string (optional) - If set, add an index field of the given name that checks the number of elements
weightsPerFieldValue: map[object, double] (optional) - Weights to apply to score for a given value.
Example
Let’s take a look at a real world example using the title field of DashboardInfo.pdl:
record DashboardInfo {
/**
* Title of the dashboard
*/
@Searchable = {
"fieldType": "TEXT_PARTIAL",
"enableAutocomplete": true,
"boostScore": 10.0
}
title: string
....
}
This annotation is saying that we want to index the title field in Elasticsearch. We want to support partial matches on
the title, so queries for Cust should return a Dashboard with the title Customers. enableAutocomplete is set to
true, meaning that we can autocomplete on this field when typing into the search bar. Finally, a boostScore of 10 is
provided, meaning that we should prioritize matches to title over matches to other fields, such as description, when
ranking.
Now, when Datahub ingests Dashboards, it will index the Dashboard’s title in Elasticsearch. When a user searches for Dashboards, that query will be used to search on the title index and matching Dashboards will be returned.
Note, when @Searchable annotation is applied to a map, it will convert it into a list with "key.toString()
=value.toString()" as elements. This allows us to index map fields, while not increasing the number of columns indexed.
This way, the keys can be queried by aMapField:key1=value1.
You can change this behavior by specifying the fieldType as OBJECT in the @Searchable annotation. It will put each key
into a column in Elasticsearch instead of an array of serialized kay-value pairs. This way the query would look more
like aMapField.key1:value1. As this method will increase the number of columns with each unique key - large maps can
cause a mapping explosion in Elasticsearch. You should not use the object fieldType if you expect your maps to get
large.
@Relationship
This annotation is applied to fields inside an Aspect. This annotation creates edges between an Entity’s Urn and the destination of the annotated field when the Entity is ingested. @Relationship annotations must be applied to fields of type Urn.
It takes the following parameters:
- name: string - A name used to identify the Relationship type.
- entityTypes: array[string] (Optional) - A list of entity types that are valid values for the foreign-key relationship field.
Example
Let’s take a look at a real world example to see how this annotation is used. The Owner.pdl struct is referenced by
the Ownership.pdl aspect. Owned.pdl contains a relationship to a CorpUser or CorpGroup:
namespace com.linkedin.common
/**
* Ownership information
*/
record Owner {
/**
* Owner URN, e.g. urn:li:corpuser:ldap, urn:li:corpGroup:group_name, and urn:li:multiProduct:mp_name
*/
@Relationship = {
"name": "OwnedBy",
"entityTypes": [ "corpUser", "corpGroup" ]
}
owner: Urn
...
}
This annotation says that when we ingest an Entity with an Ownership Aspect, DataHub will create an OwnedBy relationship between that entity and the CorpUser or CorpGroup who owns it. This will be queryable using the Relationships resource in both the forward and inverse directions.
Annotating Collections & Annotation Overrides
You will not always be able to apply annotations to a primitive field directly. This may be because the field is wrapped in an Array, or because the field is part of a shared struct that many entities reference. In these cases, you need to use annotation overrides. An override is done by specifying a fieldPath to the target field inside the annotation, like so:
/**
* Charts in a dashboard
*/
@Relationship = {
"/*": {
"name": "Contains",
"entityTypes": [ "chart" ]
}
}
charts: array[ChartUrn] = [ ]
This override applies the relationship annotation to each element in the Array, rather than the array itself. This allows a unique Relationship to be created for between the Dashboard and each of its charts.
Another example can be seen in the case of tags. In this case, TagAssociation.pdl has a @Searchable annotation:
@Searchable = {
"fieldName": "tags",
"fieldType": "URN_WITH_PARTIAL_MATCHING",
"queryByDefault": true,
"hasValuesFieldName": "hasTags"
}
tag: TagUrn
At the same time, SchemaField overrides that annotation to allow for searching for tags applied to schema fields
specifically. To do this, it overrides the Searchable annotation applied to the tag field of TagAssociation and
replaces it with its own- this has a different boostScore and a different fieldName.
/**
* Tags associated with the field
*/
@Searchable = {
"/tags/*/tag": {
"fieldName": "fieldTags",
"fieldType": "URN_WITH_PARTIAL_MATCHING",
"queryByDefault": true,
"boostScore": 0.5
}
}
globalTags: optional GlobalTags
As a result, you can issue a query specifically for tags on Schema Fields via fieldTags:<tag_name> or tags directly
applied to an entity via tags:<tag_name>. Since both have queryByDefault set to true, you can also search for
entities with either of these properties just by searching for the tag name.